I recently got sent a HUGE factory in a savegame for Production Line. It has over 600 production slots and 24 resource importers, and its MASSIVE. Here are some screenshots:
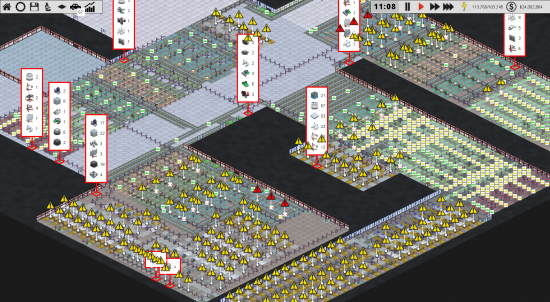

Despite its awesomeness it was MASSIVELY slow. Not only did loading it take forever, but whenever you changed any of the resource conveyors the game would hang for about 20 seconds. hardly ideal, especially given that I have an 8core i7 PC. So I set to work trying to optimize the code. I did some fairly small optimisations first, which boosted processing by 12% but I needed more fundamental re-design. After chatting to a fellow indie coder, I agreed that my currents system of always calculating the optimum route to everywhere, for everyone, when something changed, was clearly not viable. I switched over to a new system of ‘lazy’ computation. Basically when I change a route somewhere, it now sets a flag on every production slot saying ‘you should recalculate your nearest slot soon’. That flag gets checked every frame, and sometime in the next 120 frames 92 seconds) each slot will calculate the route from its location to all the importers, and store the nearest two. It needs this so slots seem to import from a sensible location, as opposed to an importer that is miles away.
This was good, and sped things up a LOT. Now instead of hanging, the game would stutter for about 10 seconds. better but nowhere near good enough. I then realised I was doing something seriously dumb. I was going through all those routes I calculated, and picking the nearest, THEN doing it again, to pick the second nearest. doh! This sped things up, but in retrospect, it was trivial, it just alerted me (alongside my profiler) to the fact that when I tried to get (for example0 15,000 routes, I actually calculated 30,000. How come?
It turns out that the code that multithreaded all of the ‘calc the routes’ code, was not storing any of the results, so the code that came after it which then went through the (not saved) routes to pick the nearest ones was having to recalculate them anyway. I was essentially doing everything twice.l Worse…this second bit of code was single threaded, meaning all my multithreaded time was wasted and all the work happened in a single thread. What a dork.
A nice simple change to the code to make sure those multithreaded route calcs are actually stored *doh* means that not only did the processing time half, it now gets split over potentially 8 cores instead of 1, so on my PC its now running 16x faster. Combine that with the earlier speed-ups and its likely 18x faster, and because of the frame-spanning over 120 frames, it *feels* fluid as hell, even on insane maps.
Here is the concurrency visualiser showing the loading of the insanely big map.
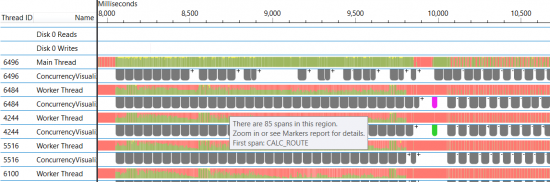
And here it is zoomed in showing the multithreaded bits.
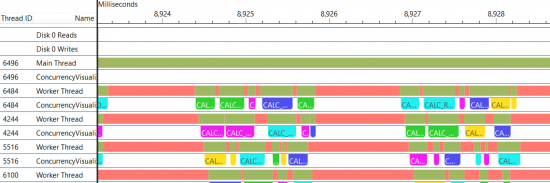
Those gaps are because each slot makes a single-threaded call to evaluate all of the import bays (each colored block is the code to get a route from one import bay to one production slot), and that call (in the main thread), then spreads it over the worker threads. Ideally I’d find time to eliminate that single thread blocking. Also I have some gaps in there because the end of each threads Calc() has to use a critical section lock to deposit its new routes safely in the main thread. Ideally I’d bunch them up inside a thread structure and dump them at the end.
Anyway, enough tech bollocks, the upshot is that massive factories will now be uber-fast :D.