So Gratuitous Space Battles 2 is running really well (50-60FPS even at dual-monitor 5120 res mode) on my dev PC. dev PC specs:
win 7 64bit 8 GB RAM, i7-3770k CPU @ 3.50 GHZ. GeForce GTX 670.
However it can drip pretty low on my HD4000 intel laptop (also an i7, but lower spec). I’ve seen things go to 25 FPS at 1600×900, although that is without all the fancy options off, so maybe it will go higher with them deselected. Ideally I’d get that much better. So what is the problem?
I think it’s too many small draw calls, and sadly, thats kinda the way my engine works.
The basic algorithm of my engine is this:
Update_Everything() (game simulation, partly multithreaded)
Check_what_is_onscreen()
SetRenderTarget()
DrawBigListOfObjectsToRenderTarget()
SetRenderTarget()
DrawBigListOfObjectsToRenderTarget()
...
CompositeAllTheTargetsIntoFinalImage()
GUI()
The problem is all of those lists of objects being drawn. The solution to this in a conventional 3D game (before you all suggest it), is to use a z-buffer, sort all those objects by render state or texture or both, and blap them in a few draw calls. Thats fab, but it doesn’t work with alpha blending. People who do 3D games think alpha blending means particles, but nope, it also means nice fuzzy edges of complex sprite objects. To do the order-independent Z-buffer rendering method, you have to disable proper alpha-blending, and then everything starts to look sharp, boxy and ugly as hell. 3D games sprinkle antialiasing everywhere to try and cover it. With complex sprites layered on top of each other, this just looks dreadful.
The solution is the good old fashioned painters algorithm, meaning drawing in Z order from back to front. This works well and everything looks lovely.

The problem is that you end up with 4,000 draw calls in a frame, and then the HD4000 explodes. Why 4,000? well to get some of my more l33t effects I need to draw a lot of objects four times, so thats only really 1,000 objects. to do proper lighting on rotated objects I can’t group objects of a different rotation, so each angle of an identical object means a separate draw call. Some of my render targets let me draw regardless of that angle, but the problem then becomes textures. If you draw painters algorithm and draw this…
ShipA
ShipB
ShipA
ShipB
Then there is no way to group the ships by texture without screwing it up, if those ships overlap. This is “a pain”. There are some simple things I can do…and I have a system that does them. For example, if I have this big list of sprites to draw and it turns out that occasionally I *do* get ShipA,ShipA Then I identify that, and optimize away the second call by making a single VertexBuffer call for both sprites. (or both particle systems, in those cases) I even have a GUI that shows me when this happens….
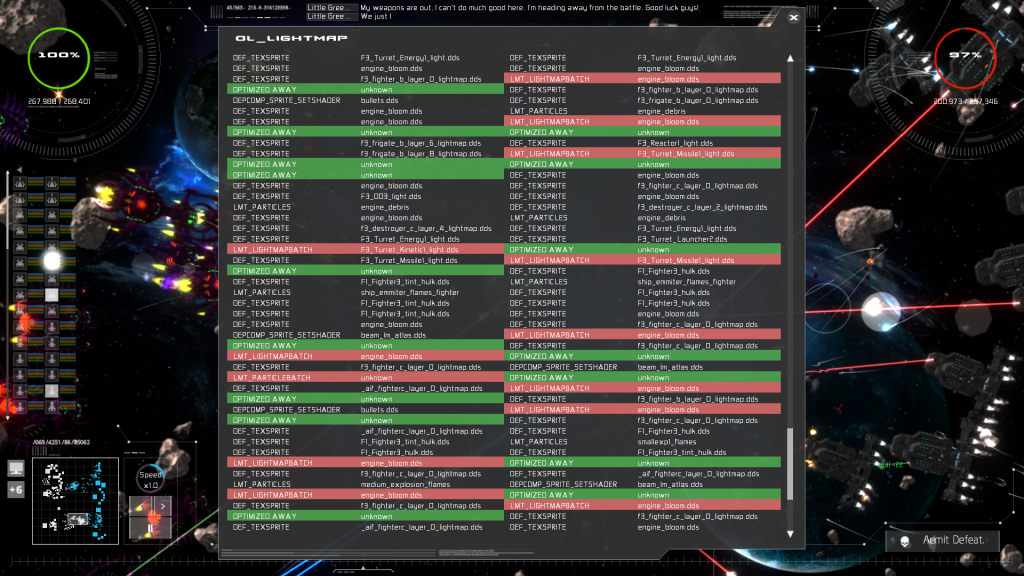
The trouble is, the majority of the time this is NOT happening. There are to my mind two potential solutions, both of them horribly messy:
1) Go through the list and calculate where I have a ‘ShipA….ShipA’ pair where there is nothing in between them that overlaps either of them, and then re-arrange them so that they are next to each other, thus allowing for a lot more grouping. (This involves some hellish sorting and overlap detection hell).
2) Pre-process everything, building up a database at the start of the rendering of which textures seem to naturally follow on from each other, then render those textures to a temporary ‘scratch’ render target atlas, which I can then index into. This would be fun to code, also amusing to watch the render target itself in the debugger :D Adds a lot of ‘changing texture pointers and UVs after the event’ complexity though.
Be aware that I’m using Direct9, mostly for compatibility reasons, which means that rendering to multiple render targets at once, or doing multithreaded rendering really isn’t an option.
Edit: just spotted a bug with method 2. If I draw 10 instances of ShipA, they may be at different Zooms, so I will only be caching (in my temp atlas) a single image, not the full mip-map chain, meaning the rendering of atlased sprites would lose effective neat mip-mapping and potentially look bad :(